Magika
Magika is a novel AI-powered file type detection tool that relies on the recent advance of deep learning to provide accurate detection. Under the hood, Magika employs a custom, highly optimized model that only weighs about a few MBs, and enables precise file identification within milliseconds, even when running on a single CPU. Magika has been trained and evaluated on a dataset of ~100M samples across 200+ content types (covering both binary and textual file formats), and it achieves an average ~99% accuracy on our test set.
Here is an example of what Magika command line output looks like:
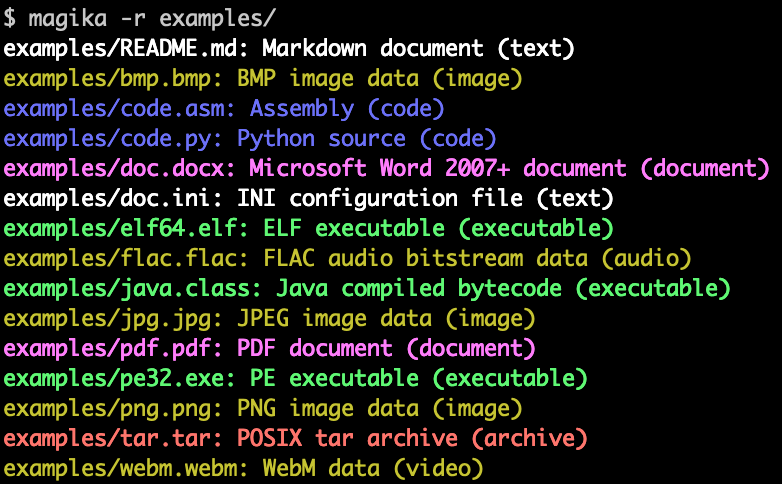
Magika is used at scale to help improve Google users’ safety by routing Gmail, Drive, and Safe Browsing files to the proper security and content policy scanners, processing hundreds billions samples on a weekly basis. Magika has also been integrated with VirusTotal (example) and abuse.ch (example).
{kind=link}
{kind=link}
For more context you can read our initial announcement post on Google’s OSS blog, and you can read more in our research paper, published at the IEEE/ACM International Conference on Software Engineering (ICSE) 2025.
You can try Magika without installing anything by using our web demo, which runs locally in your browser!
Highlights
Section titled “Highlights”- Available as a command line tool written in Rust, a Python API, and additional bindings for Rust, JavaScript/TypeScript (with an experimental npm package (which powers the web demo), and GoLang (WIP).
- Trained and evaluated on a dataset of ~100M files across 200+ content types.
- On our test set, Magika achieves ~99% average precision and recall, outperforming existing approaches — especially on textual content types.
- After the model is loaded (which is a one-off overhead), the inference time is about 5ms per file, even when run on a single CPU.
- You can invoke Magika with even thousands of files at the same time. You can also use
-rfor recursively scanning a directory. - Near-constant inference time, independently from the file size; Magika only uses a limited subset of the file’s content.
- Magika uses a pre-tuned, per-content-type threshold system that determines whether to “trust” the prediction for the model, or whether to return a generic label, such as “Generic text document” or “Unknown binary data”.
- The tolerance to errors can be controlled via different prediction modes.
- Support for all major operating systems.
- The client and the bindings are already open source, and more is coming soon!